1. 왜 예쁜 JPG만으로는 부족했는가

제가 AI 이미지 생성에 본격적으로 빠져든 건 2022~23년, Craiyon과 Midjourney가 세상에 처음 나올 때였습니다. 평소에 그림을 그리고 싶었지만 실력이 최악이라는 걸 누구보다 잘 알고 있었기에, AI가 이미지를 만들어준다는 걸 보자마자 "와, 이건 된다!" 싶었죠. 당시 다니던 회사에 'AI 도입하자'라고 줄기차게 주장하고 다녔습니다.
다만 영화나 실제 상업 프로젝트를 진행하다 보면, 단순히 예쁜 JPG로는 어딘가 공허했습니다. 겉표지만 화려하고 내용은 비어 있는 책 같달까요. 아무리 비주얼이 훌륭해도 실제 후반작업에 집어넣는 순간 무너져버렸습니다.
문제는 색감/화질이 아니라 데이터 그 자체 였습니다.
영화 현장을 생각해 보면 쉽습니다. 촬영 감독이 카메라로 장면을 찍으면, 그 파일은 우리가 모니터에서 보는 JPEG 이미지와 전혀 다른 형태로 저장됩니다. 빛의 밝고 어두움 정보를 최대한 날것 그대로 담은 데이터죠. 이걸 이용해서 색보정, 합성, CG 작업을 하게 됩니다. AI가 만들어주는 이미지가 아무리 예뻐도, 이 '날것의 데이터' 수준을 못 맞추면 영화 파이프라인에선 쓸 수가 없었습니다.

더 구체적으로 말하면 이렇습니다. 일반 이미지(SDR, Standard Dynamic Range)는 우리 눈에 보기 좋게 이미 처리된 결과물입니다. 반면 영화 현장에서 쓰는 HDR은 "High Dynamic Range, " 즉 빛의 밝고 어두운 범위를 훨씬 넓게 담은 데이터입니다. 핸드폰 설정에서 보던 'HDR 사진'과 비슷한 개념이지만, 훨씬 전문적이고 수치적인 의미입니다. 창문 밖 눈부신 햇빛부터 어두운 구석 그림자까지, 한 장면 안에서 극단적으로 다른 밝기를 모두 정보로 보존하는 것이 목표입니다.
그리고 2026년인 지금, "AI가 HDR 수준의 데이터를 만들 수 있냐"는 질문에 진지하게 답하려는 연구들이 쏟아지기 시작했습니다.
저는 이게 AGI(범용 인공지능)가 아닌 VGI(VFX General Intelligence), 즉 영상 제작 현장을 위한 진짜 AI로 가는 첫 단추라고 생각합니다.
2. AI로 HDR을 뽑는 세 가지 방향
현재까지 AI로 HDR을 뽑는 시도는 크게 세 갈래로 나눌 수 있습니다.
2-1. 컬러 사이언스 기반 -- "있는 것을 더 넓게 펼치는" HDR

첫 번째는 이미 완성된 SDR 이미지를 기반으로 HDR처럼 확장하는 방식입니다. 비유하자면 8비트짜리 오래된 사진을 포토샵 보정으로 더 풍부하게 만드는 것에 가깝습니다. 하이라이트(밝은 부분), 노출, 색감의 범위를 AI가 수학적으로 늘려줍니다.
장점은 명확합니다. 결과가 예측 가능하고, 아티스트가 직접 조정하기 쉬우며, 기존 영화 후반작업 흐름에 그대로 끼워 넣을 수 있습니다.
하지만 치명적인 한계가 있습니다. 처음부터 SDR 안에서 사라진 정보는 어떻게 해도 복구가 안 됩니다. 예를 들어 창문이 완전히 하얗게 날아간 사진이 있다면, 그 흰색 픽셀을 AI가 아무리 처리해도 실제 창밖 하늘이나 구름, 빛의 정보를 다시 만들어낼 수 없습니다. 이미 지워진 건 지워진 거니까요.
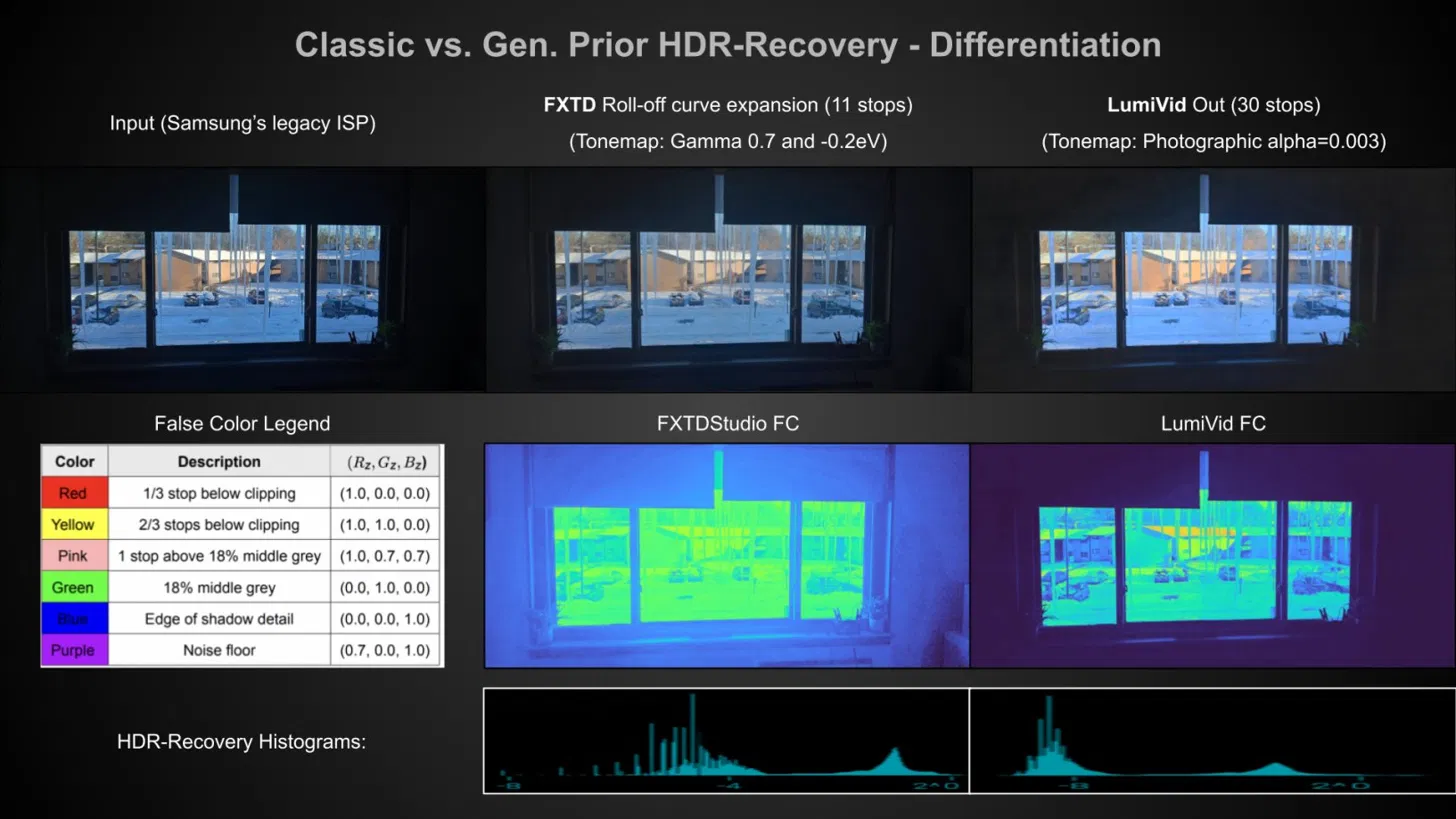
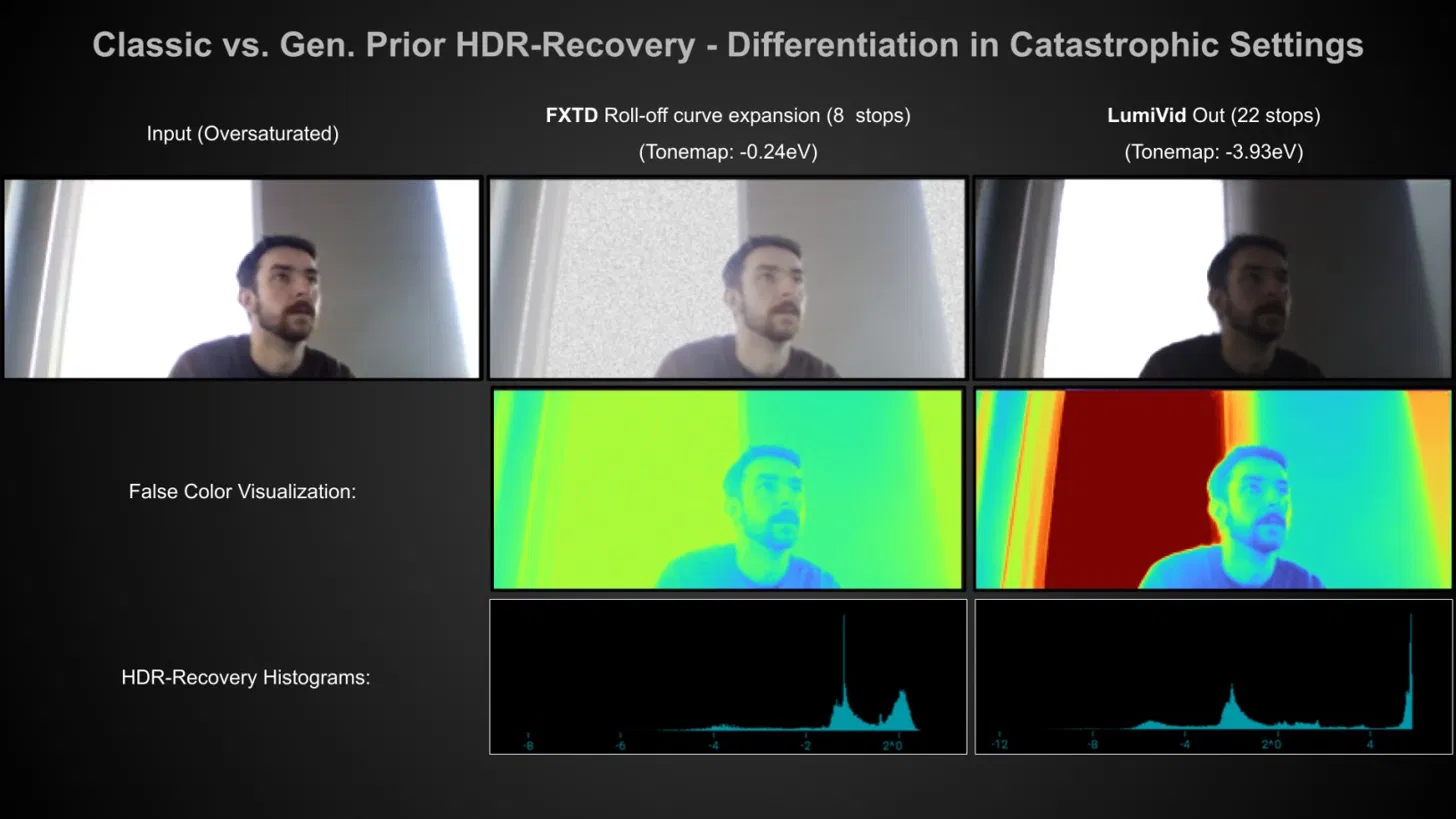
숫자상으로 Dynamic Range(빛을 담는 범위)는 늘어나도, 실제 디테일은 여전히 비어 있는 거죠.
실제 비교 수치를 보면 이 한계가 얼마나 명확한지 알 수 있습니다. FXTD Radiance가 같은 장면에서 확보하는 밝기 범위가 약 11 stops(노출 단계를 세는 단위) 수준인 반면, 뒤에서 소개할 생성형 AI 방식은 같은 장면에서 30 stops를 뽑아냅니다. 노출이 심하게 무너진 영상에서는 격차가 더 벌어져 FXTD는 8 stops, 생성형은 22 stops까지 차이가 납니다.
2-2. 생성 모델 기반 -- "장면을 이해해서 새로 채우는" HDR
대표: LumiVid (Lightricks), X2HDR (홍콩시립대 / 모나쉬대 / 캠브리지대)
두 번째 방향이 최근 가장 흥미로운 연구들입니다. 단순히 있는 정보를 늘리는 게 아니라, AI가 장면 자체를 이해한 뒤 사라진 빛의 정보를 논리적으로 채워 넣는 방식입니다.
핵심 아이디어부터 설명하면 이렇습니다.
요즘 AI 이미지 생성 모델(Stable Diffusion, FLUX 등)은 모두 일반적인 SDR 이미지로 학습되어 있습니다. 당연히 HDR 데이터는 본 적이 없습니다. 그렇다고 처음부터 HDR용 모델을 새로 만들면 엄청난 데이터와 비용이 필요합니다. 그래서 이 연구들은 HDR 데이터를 기존 AI 모델이 이해할 수 있는 형태로 '번역'한 뒤, 모델을 최소한만 재훈련시키는 것을 선택했습니다.
비유하자면, 영어만 하는 선생님에게 한국 요리를 가르치려고 할 때, 요리를 영어로 설명한 레시피로 바꿔서 건네주는 것과 비슷합니다. 선생님을 바꾸는 게 아니라, 전달 방식을 바꾸는 거죠.
두 논문이 각각 어떻게 접근하는지 살펴보겠습니다.
LumiVid (Lightricks × Tel Aviv University)

목표: 일반 SDR 영상 → HDR 영상으로 변환
LumiVid는 HDR 데이터를 LogC3라는 방식으로 변환합니다. LogC3는 Arri 같은 시네마 카메라 제조사들이 실제로 현장에서 쓰는 log 커브입니다. 빛의 밝기를 수학적으로 압축해서, 기존 AI 모델이 평소에 보던 SDR 이미지의 통계 분포와 최대한 비슷하게 만들어줍니다. 여러 변환 방식을 실측 비교한 결과, LogC3가 AI 모델의 내부 공간과 가장 잘 맞는 분포를 만들어냈습니다.
학습 방식도 똑똑합니다. HDR 영상을 LogC3로 변환해 AI에게 '정답'으로 주면서, 동시에 같은 장면을 의도적으로 일반 SDR처럼 열화 시킨 버전을 '문제'로 줍니다. MP4 압축, 블러, 대비 왜곡 등 실제 SDR 영상에서 일어나는 열화를 흉내 낸 거죠. AI는 "이 망가진 SDR에서 어떻게 HDR을 복원하냐"를 배우게 됩니다.
가장 인상적인 점은 규모 대비 효율입니다. 전체 AI 모델 파라미터의 1% 미만만 재훈련해도 되고 (LoRA라는 경량 훈련 기법 덕분에), 단일 GPU 한 대로 약 8시간이면 학습이 끝납니다. 그리고 최종 출력이 float16 EXR — 영화 후반작업 현장에서 바로 쓸 수 있는 전문 포맷입니다. 또 하나의 강점은 영상 전체의 일관성입니다. 이미지 한 장씩 처리하는 방식이 아니라 영상 클립 전체를 한 번에 처리하기 때문에, 프레임마다 노출값이 들쭉날쭉한 문제(flickering)가 거의 없습니다. ARRI 전문 촬영본으로 외부 평가를 했을 때도 기존 방법들을 앞섰습니다.
단점도 있습니다. SDR에 원래 없던 정보, 예를 들어 완전히 날아간 하이라이트 안의 디테일은 결국 AI가 '상상'해서 채워야 합니다. 긴 영상에서는 이 상상이 어긋나거나 일관성이 무너지는 위험이 있습니다. 아무리 flickering이 없고, 전문가 방식처럼 해도, 제작자가 원하는 이미지가 변형이 된다면 아직은 AGI가 아닌 거로 봅니다.
X2HDR (홍콩시립대 / 모나쉬대 / 캠브리지대)

목표: 텍스트 → HDR 이미지 생성, 또는 RAW 사진 → HDR 이미지 재건축
X2HDR은 비슷한 아이디어를 이미지에 적용했습니다. 기반 모델은 많이 들어보셨을 오픈소스 이미지 생성 AI인 FLUX.1-dev입니다.
이 논문의 핵심 발견은 하나의 실험에서 나왔습니다. HDR 이미지를 있는 그대로 FLUX의 내부 압축 장치(VAE)에 집어넣으면 결과물이 심각하게 뭉개집니다. 그런데 PU21이라는 방식으로 먼저 변환하면 또는 더 쉽게 말하자면 인간의 눈이 빛을 인식하는 방식에 맞게 데이터를 재분배하면, 일반 SDR 이미지와 거의 동등한 수준으로 처리됩니다.
PU21이 하는 일을 쉽게 설명하면 이렇습니다. HDR 데이터는 밝은 영역에 값이 극단적으로 몰려 있어 AI가 처리하기 어렵습니다. PU21은 이걸 인간의 시각에 맞게 재분배해서 , 밝은 쪽은 압축하고, 어두운 쪽에 더 많은 해상도를 배분해서, AI가 이해하기 좋은 형태로 바꿔줍니다.
이를 기반으로 X2HDR은 두 가지 모드를 제공합니다:
텍스트 → HDR: 프롬프트만 입력하면 HDR 이미지가 생성됩니다. "모닥불이 타오르는 밤하늘" 같은 프롬프트에서 하이라이트와 쉐도우가 모두 살아 있는 HDR 결과물이 나옵니다. 평균 약 14.2 stops의 Dynamic Range를 확보했습니다.
RAW → HDR: 여기서 한 가지 흥미로운 개념이 등장합니다.
SDR → HDR = 이미 인화된 사진을 보고 "원래 창밖에 뭐가 있었을까"를 상상하는 것
RAW → HDR = 현상 전 필름 네거티브를 보고 정보를 복원하는 것
카메라로 촬영할 때 RAW 파일은 카메라 내부의 이미지 처리 전 단계, 즉 센서가 잡아낸 빛 신호를 거의 그대로 저장합니다. 그래서 SDR JPEG보다 하이라이트와 쉐도우 정보가 훨씬 많이 남아 있습니다. X2HDR은 이 RAW 파일을 입력으로 받아 더 신뢰도 높은 HDR을 재건축합니다. 실제로 연구자들이 사람을 대상으로 한 화질 비교 실험에서, X2HDR의 RAW2HDR 결과물이 실제 HDR 원본에 거의 근접한 것으로 평가됐습니다.
단점은 이미지 한 장씩 처리하는 모델이다 보니, 영상에 적용할 때 프레임마다 결과가 달라지는 문제가 생깁니다. 또 seed(생성 난수), 추론 단계 수, 프롬프트에 따라 Dynamic Range 폭이 달라질 수 있어 '물리적으로 정확한 HDR'이라기보다는 '그럴듯한 HDR'에 가까울 수 있습니다.
2-3. Raw Output Mining -- "원래 숨어 있던 정보를 꺼내는" HDR

대표: FLUX2-Dev 관찰 실험 — Aryan Garg (Flux Creator 멤버)
세 번째는 논문이 아닌 실험적 관찰에 가깝습니다. 하지만 어떤 면에서는 가장 근본적인 질문을 던지고 있습니다.
모든 AI 이미지 생성기는 최종 이미지를 출력하기 전에 값을 [-1, 1] 범위 안으로 잘라냅니다. 스크린에 보여주기 좋게 표준화하는 과정입니다. 그런데 FLUX2-Dev의 AI가 이미지를 만든 직후, 이 '정리' 과정을 거치기 전의 원시 데이터를 들여다본 결과가 흥미롭습니다.
흰색보다 더 밝은 값(+1.2 이상)과 검정보다 더 어두운 값(-1.4 이하)이 나타난 것입니다.
처음엔 단순한 연산 오류처럼 보입니다. 그런데 이 범위를 벗어난 픽셀들을 지도처럼 시각화해 보면, 무작위 노이즈가 아니라 장면의 구조를 따라가는 패턴이 보입니다. 도쿄 밤거리 인물 사진 실험에서 실제로 확인된 결과를 보면 — '범위 초과 어두운 픽셀' 맵에는 배경 건물과 도로 그림자 구조가, '범위 초과 밝은 픽셀' 맵에는 차량 헤드라이트와 간판 조명 위치가 나타납니다. 단순 노이즈라면 이런 패턴이 나올 수 없습니다.
Flux Creator Aryan Garg의 가설은 이렇습니다:
"수십억 장의 이미지로 학습된 AI 모델은, 빛과 그림자의 구조를 이미 내부적으로 이해하고 있는 것일 수 있다. 그런데 우리가 화면 출력을 위해 데이터를 잘라내는 과정에서 그 정보를 버리고 있는 것은 아닐까?"
물론 이 값들이 실제로 HDR 수준의 의미 있는 데이터인지 검증이 필요합니다. "FLUX2 = HDR"이라고 단정하기엔 아직 이릅니다. 하지만 앞서 소개한 LogC3나 PU21 같은 변환 방식을 이 원시 데이터에 적용한다면, 별도의 훈련 없이 FLUX2 안에서 숨어 있는 Dynamic Range를 찾을 수 있지 않을까 하는 가능성입니다.
더 나아가 Aryan Garg가 탐색 중인 방향은 영역별 Dynamic Range 제어입니다. 이미지 전체를 일괄 처리하는 게 아니라, 하늘, 창문, 얼굴, 조명처럼 장면의 각 요소마다 밝기 범위를 따로 조정하는 것이죠. AI가 이미 장면을 구조적으로 이해하고 있다면, 이론적으로 가능한 이야기입니다.
3. 진짜 복구인가, 그럴듯한 생성인가 — 세 가지 층위
세 방향을 정리하면서 한 가지 중요한 구분이 필요합니다. 모든 AI HDR이 같은 게 아닙니다.
| 담을 수 있는가 | 그릇이 HDR 값을 보관할 공간이 있나 | Raw VAE Output Mining |
| 복원할 수 있는가 | 원본 신호에서 실제 정보를 되살리나 | RAW2HDR (X2HDR) |
| 상상해서 채우는가 | 없는 정보를 AI가 그럴듯하게 만드나 | SDR2HDR (LumiVid, X2HDR) |
Radiance 같은 첫 번째 방향은 주로 '펼치기'입니다. LumiVid와 X2HDR은 '담기 + 상상해서 채우기'입니다. RAW2HDR은 '복원' 성격이 더 강하고, SDR2HDR은 '상상' 성격이 더 강합니다.
어느 것이 옳고 그르냐의 문제가 아닙니다. 영화를 공부하면서 늘 느꼈던 것처럼, 영화에는 정답이 없고 HDR에도 정답이 없습니다. 다만 각 방법이 어느 층위에 있는지 알아야, 내가 원하는 결과에 맞는 도구를 선택할 수 있습니다.
4. 왜 이것이 VGI의 첫 단추인가
VGI, 즉 VFX를 위한 범용 AI는 단순히 '예쁜 이미지를 만드는 AI'가 아닙니다.
최소한 AI로 만든 데이터들은 영화 VFX 현장에서 AI가 실제로 쓸모 있으려면, 현장의 기술 언어를 이해해야 합니다. 장면의 빛을 수치로 다루는 방법, 카메라 반응 곡선, 색상 공간 변환, 합성 시 레이어 간 빛의 물리적 일관성 같은 것들이죠.
AI로 HDR을 뽑는다는 건 단순히 밝은 이미지를 만든다는 뜻이 아닙니다. AI가 영화 후반작업의 기술 언어를 조금씩 이해하기 시작했다는 신호에 가깝습니다. LumiVid가 Arri 카메라의 LogC3을 선택한 것도, X2HDR이 인간 시각 기반의 PU21을 쓴 것도, 그냥 기술적 선택이 아니라 "AI에게 영화 현장의 언어를 가르치는" 시도입니다.
5. 앞으로 남은 가장 큰 과제: 제어 가능성
현재 AI HDR의 핵심 문제는 HDR을 '만드는 것' 자체보다 HDR을 '제어하는 것'입니다.
영화 현장에서는 "좋아 보이는 HDR"보다 "내가 원하는 대로 반복 가능한 HDR"이 훨씬 중요합니다. 지금은 AI가 얼마나 넓은 밝기 범위를 생성할지가 대부분 학습 데이터와 모델 내부 가정에 의해 결정됩니다. 프로덕션 현장에선 이게 너무 불안정합니다.
앞으로 제가 생각하기엔 필요한 기능들을 나열하면 이렇습니다:
- 최대 밝기 수치 직접 지정
- 노출값(Exposure Value) 직접 제어
- 하이라이트 복원 강도, 쉐도우 확장 강도 조절
- 특정 영역만 HDR 처리하는 마스크 기능
- "상상 금지 모드" — 있는 정보만 복원하고 만들어내지 않기
- 시간축 일관성 고정 — 영상 전체에서 노출값이 흔들리지 않도록
이 중 앞서 언급한 영역별 Dynamic Range 제어가 가장 흥미롭습니다. 하늘과 창문과 얼굴과 조명에 각각 다른 밝기 정책을 독립적으로 적용할 수 있다면, 이건 단순한 HDR 생성을 넘어서 AI가 색보정 도구 자체가 되는 이야기입니다.
마치며
2022년에 Midjourney 앞에서 "와, 이건 된다!" 했던 그 흥분이, 2026년에는 조금 다른 방향을 향하고 있습니다. 예쁜 이미지가 아니라, 후반작업 가능한 데이터. 표면이 아니라, 파이프라인 쪽으로요.
Radiance처럼 기존 이미지를 더 넓게 펼치는 방향, LumiVid/X2HDR처럼 AI의 이해를 바탕으로 재건축하는 방향, Aryan Garg처럼 AI 안에 이미 숨어 있는 정보를 꺼내는 방향이 존재하며, 셋 다 옳고 셋 다 아직 미완성이라고 생각합니다. 하지만 방향은 보입니다. AI가 영화 현장의 기술 언어를 이해하는 방향으로 슬슬 움직이고 있습니다. 이제 막 첫 단추를 꿰고 있는 중이라고 생각합니다.
지금이 안된다 하더라도, 곧 VGI가 도달되었으면 합니다.
DiBlat AI Researcher
Seung Oh Jung.
참고 논문:
- X2HDR: HDR Image Generation in a Perceptually Uniform Space — Wu et al., City University of Hong Kong / Monash University / University of Cambridge (2026)
- LumiVid: HDR Video Generation via Latent Alignment with Logarithmic Encoding — Korem et al., Lightricks / Tel Aviv University (2026)
- Aryan Garg, FLUX2-Dev raw VAE output observation (2026)
'AI' 카테고리의 다른 글
| Midjourney Medical의 시초: Whole cross-sectional human ultrasoundtomography (1) | 2026.06.19 |
|---|---|
| AI 혁신이라던 힉스필드(Higgsfield)의 민낯 (0) | 2026.02.07 |
| [AI 과외 선생] 과연 AI는 수포자를 살릴수 있을까? (4) | 2024.12.31 |
| Iruletheworldmo 의 OpenAI 추후 플랜 ? (1) | 2024.08.11 |
| Quiet-STaR: Language Models Can Teach Themselves to Think Before Speaking 논문 리뷰 (9) | 2024.08.11 |